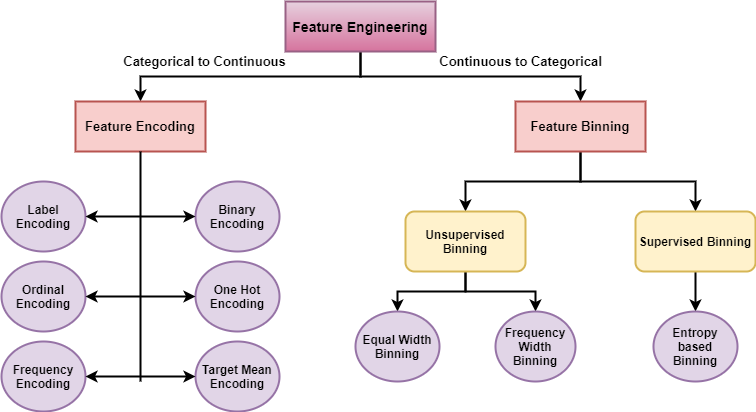
Encoding is a critical step in the data preprocessing stage of any data science project. It involves transforming categorical data into a numerical format so that machine learning algorithms can process it. Several encoding methods are used in data science, each with its own advantages and appropriate use cases. Understanding these methods is essential for anyone looking to work effectively with data. Enrolling in a data science course in Mumbai can provide a comprehensive understanding of these techniques and their applications.
Label Encoding
Label encoding is one of the simplest encoding methods, where each unique category is assigned an integer value. This method is straightforward and seamless to implement, but it can introduce ordinal relationships between categories that do not exist. For example, if you encode colors like red, blue, and green as 0, 1, and 2, respectively, the model might incorrectly assume an ordinal relationship between these colors.
A data science course covers the basics of label encoding and highlights when it is appropriate to use this method. Students learn about its advantages and limitations, ensuring they can make informed decisions when preprocessing categorical data.
One-Hot Encoding
One-hot encoding is a popular method in which each category is represented as a binary vector. Each position in the vector corresponds to a unique category, with “1” indicating its presence and “0” indicating its absence. This method avoids the issue of introducing ordinal relationships, making it suitable for nominal categorical data.
A data science course in Mumbai provides hands-on experience with one-hot encoding. The vibrant tech ecosystem in Mumbai offers numerous opportunities for students to work on real-world projects, applying one-hot encoding to various datasets. This practical experience is invaluable for truly understanding the nuances of this encoding method.
Binary Encoding
Binary encoding is a compromise between label encoding and one-hot encoding. It converts the integer representation of a category into its binary form and then splits the binary digits into separate columns. This method reduces the data’s dimensionality compared to one-hot encoding while mitigating the risk of introducing ordinal relationships.
By taking a data science course, students can learn how to implement binary encoding and understand its advantages in terms of reducing dimensionality and preserving data relationships. This method is specifically helpful when dealing with high-cardinality categorical features.
Frequency Encoding
Frequency encoding assigns each category a value based on the frequency of its occurrence in the dataset. This method is useful when the frequency of categories carries meaningful information that could help the model make better predictions. However, it can also introduce bias if the frequency distribution is not representative of the entire population.
A data science course in Mumbai includes training on frequency encoding and teaching students how to calculate and apply these values. The course also covers the potential pitfalls of this method and how to address them in practice.
Target Encoding
Target encoding, also known as mean encoding, involves replacing each category with the mean value of the target variable for that category. This method can provide significant predictive power but also carries the risk of overfitting, especially if not properly regularized. It is commonly used in regression problems.
A data science course provides insights into target encoding, including techniques for regularization to prevent overfitting. Students learn how to implement target encoding in different contexts and understand its impact on model performance.
Hashing Encoding
Hashing encoding, or the Hashing Trick, uses a hash function to convert categories into a fixed number of columns. This approach is particularly useful for handling high-cardinality categorical features and large datasets, as it reduces the dimensionality and memory footprint. However, it introduces the risk of hash collisions, where different categories map to the same column.
A data science course in Mumbai offers practical training on hashing encoding. Students learn how to apply this method effectively and manage the risk of collisions. The course includes real-world examples and projects that illustrate the advantages and various challenges of this approach.
Conclusion
Encoding methods are vital to data preprocessing in data science. They transform categorical data into numerical formats that machine learning algorithms can process. Each technique has its own use cases and considerations, from label encoding and one-hot encoding to more advanced methods like binary encoding, frequency encoding, target encoding, and hashing encoding. Enrolling in a data science course is an excellent choice for those looking to master these encoding methods and apply them effectively in real-world scenarios.
Business Name: ExcelR- Data Science, Data Analytics, Business Analyst Course Training Mumbai
Address: Unit no. 302, 03rd Floor, Ashok Premises, Old Nagardas Rd, Nicolas Wadi Rd, Mogra Village, Gundavali Gaothan, Andheri E, Mumbai, Maharashtra 400069, Phone: 09108238354, Email: [email protected].



